Horse racing game win probability
When gathering with family, we like to play yard, card, and board games. On a recent visit, one of the favorite games was the Across the Board Kentucky Derby Horse Racing Game. The game produced a lot of cheers and jeers and provided a fun diversion with no skill and little concentration required. After losing a little money, though, I lost interest in playing the game and decided to write some R code to simulate the game and generate win probabilities.
The game involves dealing a deck of cards (with Kings and Aces removed) to any number of players (well, up to 44 players where each player would be dealt one card). The cards in a player's hand represent wagers on the winning horse where horses are numbered 2-12 and the jack and queen cards represent 11 and 12, respectively. Two dice are rolled and the total of the dice determines which horse moves around the board. The number of steps for a horse to win is scaled roughly in proportion to the probability of that number being rolled. Below we enumerate all of the possible rolls with expand.grid, calculate the probability of each roll, and compare those probabilities to the probabilities based on the number of steps included on the game board.
rolls_df = expand.grid(dice1 = 1:6, dice2 = 1:6) |>
dplyr::mutate(roll = dice1 + dice2) |>
dplyr::count(roll) |>
dplyr::mutate(roll = as.factor(roll),
steps = c(3, 6, 8, 11, 14, 16, 14, 11, 8, 6, 3),
prob = n/sum(n),
prob_steps = steps/sum(steps))
> rolls_df
roll n steps prob prob_steps
1 2 1 3 0.02777778 0.03
2 3 2 6 0.05555556 0.06
3 4 3 8 0.08333333 0.08
4 5 4 11 0.11111111 0.11
5 6 5 14 0.13888889 0.14
6 7 6 16 0.16666667 0.16
7 8 5 14 0.13888889 0.14
8 9 4 11 0.11111111 0.11
9 10 3 8 0.08333333 0.08
10 11 2 6 0.05555556 0.06
11 12 1 3 0.02777778 0.03
We can use the sample function to simulate rolling the dice.
roll <- function(n, replace = TRUE, rdf = rolls_df){
sample(rdf$roll, size = n, replace = replace, prob = rdf$prob)
}
> round(table(roll(500000))/500000, 3)
2 3 4 5 6 7 8 9 10 11 12
0.028 0.056 0.083 0.112 0.139 0.166 0.139 0.110 0.084 0.056 0.028
With this basic setup, all horses have an equal probability of winning. The game dynamics are made more interesting by introducing scratches, i.e., horses that are not able to participate in a race. We can use our roll function to generate the scratches. The number of scratches is always four different horses.
> roll(4, replace = FALSE)
[1] 8 5 4 3
The scratches determine how much players must contribute to the kitty. The first scratch horse is 1x and the last is 4x. Players pay the scratch value for every card in their hand that matches a scratch horse. We played with quarters so the starting kitty was always $10. Every time a player rolls a value that matches the scratch horse, they have to contribute that scratch amount to the kitty. The following function calculates the value of the kitty with each subsequent roll of the dice.
get_kitty <- function(base_value, scratches, rolls = NULL){
init = 4 * base_value * (4 + 3 + 2 + 1) # multiply by 4 for 4 suits in deck
vals = NULL
if (!is.null(rolls) & length(rolls) > 0){
vals = sapply(rolls, function(x){
ind = which(scratches == x)
val = if (length(ind) > 0) ind * base_value else 0})
}
cumsum(c(init, vals))
}
> base_value = 0.25
> scratches = roll(4, FALSE)
> rolls = roll(15)
> get_kitty(base_value, scratches)
[1] 10
> scratches
[1] 6 7 10 4
> rolls
[1] 8 2 10 7 8 6 7 8 8 8 9 8 8 8 12
> get_kitty(base_value, scratches, rolls)
[1] 10.00 10.00 10.00 10.75 11.25 11.25 11.50 12.00 12.00 12.00 12.00 12.00 12.00 12.00 12.00 12.00
The probability of winning at any point in the game is the probability that a number is rolled raised to the number of steps remaining for that horse to win. That captures the basic logic of the calculations, but all of the code is available through GitHub.
> rolls_df$steps
[1] 3 6 8 11 14 16 14 11 8 6 3
> table(rolls)
2 3 4 5 6 7 8 9 10 11 12
1 0 0 0 1 2 8 1 1 0 1
> rolls_df$steps - table(rolls)
2 3 4 5 6 7 8 9 10 11 12
2 6 8 11 13 14 6 10 7 6 2
> round(rolls_df$prob^(rolls_df$steps - table(rolls)), 4)
2 3 4 5 6 7 8 9 10 11 12
8e-04 0e+00 0e+00 0e+00 0e+00 0e+00 0e+00 0e+00 0e+00 0e+00 8e-04
I ran 10,000 simulations of the game to determine which horses win most often. 2 or 12 each win 19% of the time, 3/11 = 9%, 4/10 = 10-11%, 5/9 = 6%, 6/7/8 = 4%. The primary driver behind that outcome is that 2 and 12 are less likely to end up as scratches than 3 and 11 and so on. The slightly better outcome for 4/10 than 3/11 is a byproduct of how the board is discretized and is evident in rolls_df where the prob is higher than the prob_steps for 4/10.
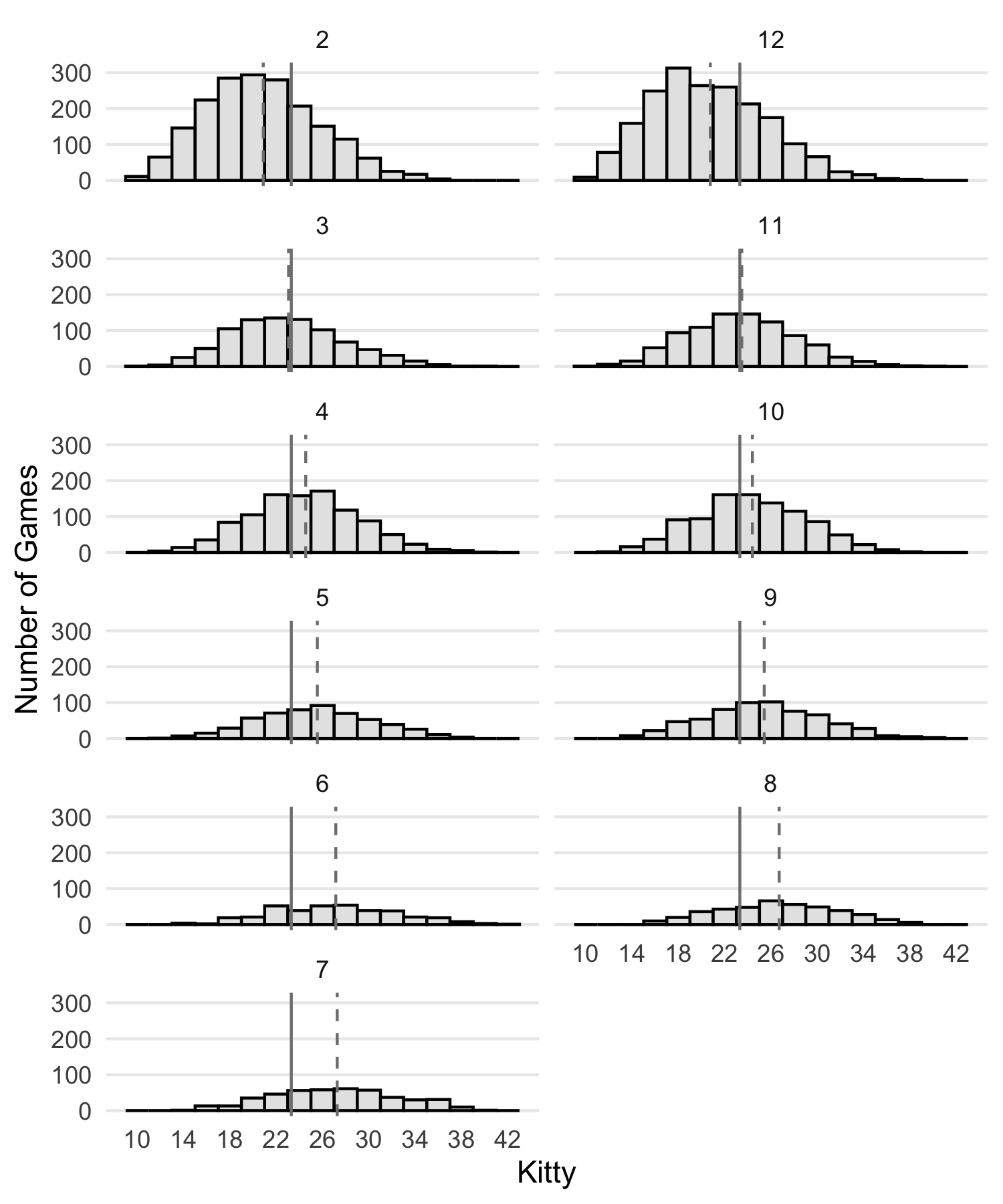
The figure below shows the kitty distribution paneled by the winning horse for those 10,000 simulated games. The solid vertical line is the overall average kitty and the dashed vertical line is the mean for each panel. The kitty grows largest in games where 6/7/8 win because it takes the most steps for those horses to make it around the board.
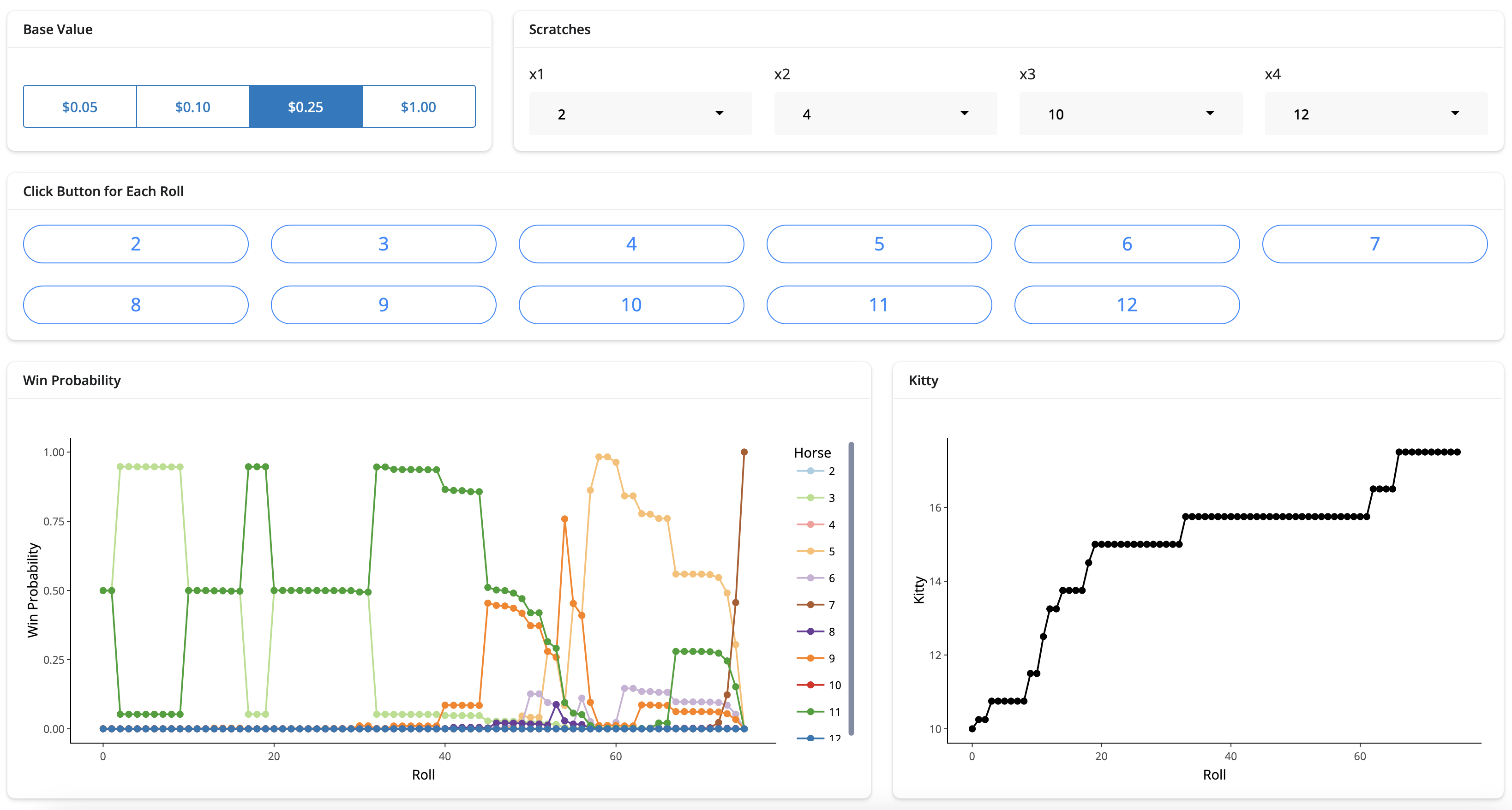
Lastly, I thought it would be fun to record the game live and provide updates on which horse was most likely to win as the game progressed. I was initially doing that within my original R script, but I decided to make a Shiny app to facilitate that process. The app layout is not great (e.g., buttons are too big) and it is missing some useful functionality (e.g., roll history not displayed and not able to undo if wrong button was clicked). The image below shows the app after I not so randomly clicked buttons to show example plots.
I suspect that I could have solved this problem more directly with math, but I had fun writing the code. My initial version performed a lot of the calculations within dataframes using dplyr functionality. I found that approach intuitive, but it was slow so I rewrote it with the vector approach (see repo).